
9 architectures RAG que chaque développeur IA devrait connaître : un guide complet avec des exemples

- Voici 3 points clés en français pour résumer le contenu :
- • RAG (Retrieval-Augmented Generation) est une technique qui améliore les modèle, il convient le mieux aux environnements à faibles enjeux où la vitesse est plus importante que la densité factuelle absolue.
- • Le Standard RAG traite la récupération comme une simple recherche ponctuelle. Il existe pour ancrer un modèle dans des données spécifiques sans l’overhead du fine-tuning, mais il suppose que votre moteur de récupération est parfait.
|
Important
|
Traduction du site Source Cet article est la version Française de 9 RAG Architectures Every AI Developer Should Know: A Complete Guide with Examples par Auteur Inconnu. |
9 Architectures RAG :
Un Guide Complet Avec Des Exemples
TLDR Le RAG optimise les sorties des modèles linguistiques en les faisant référencer des bases de connaissances externes avant de générer des réponses. Le RAG convient le mieux aux environnements à faible risque où la vitesse est plus importante que la densité factuelle absolue. Dans une configuration standard, si un utilisateur pose une question simple comme “Combien ça coûte ?”, le RAG suivra une question standard.
Votre chatbot a affirmé avec confiance à un client que votre politique de retour est de 90 jours. C’est 30. Il a plus tard décrit des fonctionnalités que votre produit n’a même pas.
Voici l’écart entre une démo impressionnante et un système de production réel. Les modèles linguistiques semblent sûrs même s’ils sont faux, et dans la production, cela devient cher très rapidement.
C’est pourquoi les équipes sérieuses d’IA utilisent RAG. Pas parce qu’il est à la mode, mais parce qu’il maintient les modèles ancrés dans des informations réelles.
Ce que la plupart des gens manque à comprendre, c’est qu’il n’existe pas un seul RAG. Il existe plusieurs architectures, chacune résolvant un problème différent. Choisissez la mauvaise, et vous gâchez des mois.
Ce guide détaille les architectures RAG qui fonctionnent vraiment en production.
Commençons par apprendre à connaître Rag.
Qu’est-ce que RAG et pourquoi cela compte vraiment ?
Avant de plonger dans les architectures, assurons-nous de bien comprendre ce dont nous parlons.
RAG optimise les sorties des modèles linguistiques en leur faisant référencer des bases de connaissances externes avant de générer des réponses. Au lieu de se fier uniquement à ce que le modèle a appris pendant l’entraînement, RAG tire des informations pertinentes et actuelles de vos documents, bases de données ou graphiques de connaissances.
Voici le processus en pratique.
- Lorsqu’un utilisateur pose une question, votre système RAG récupère d’abord des informations pertinentes à partir de sources externes en fonction de cette requête.
- Ensuite, il combine la question originale avec ce contexte récupéré et envoie tout au modèle linguistique.
- Le modèle génère une réponse ancrée dans des informations réelles et vérifiables plutôt que simplement ses données d’entraînement.
Les vrais problèmes que RAG résout
1. RAG standard : Commencez ici
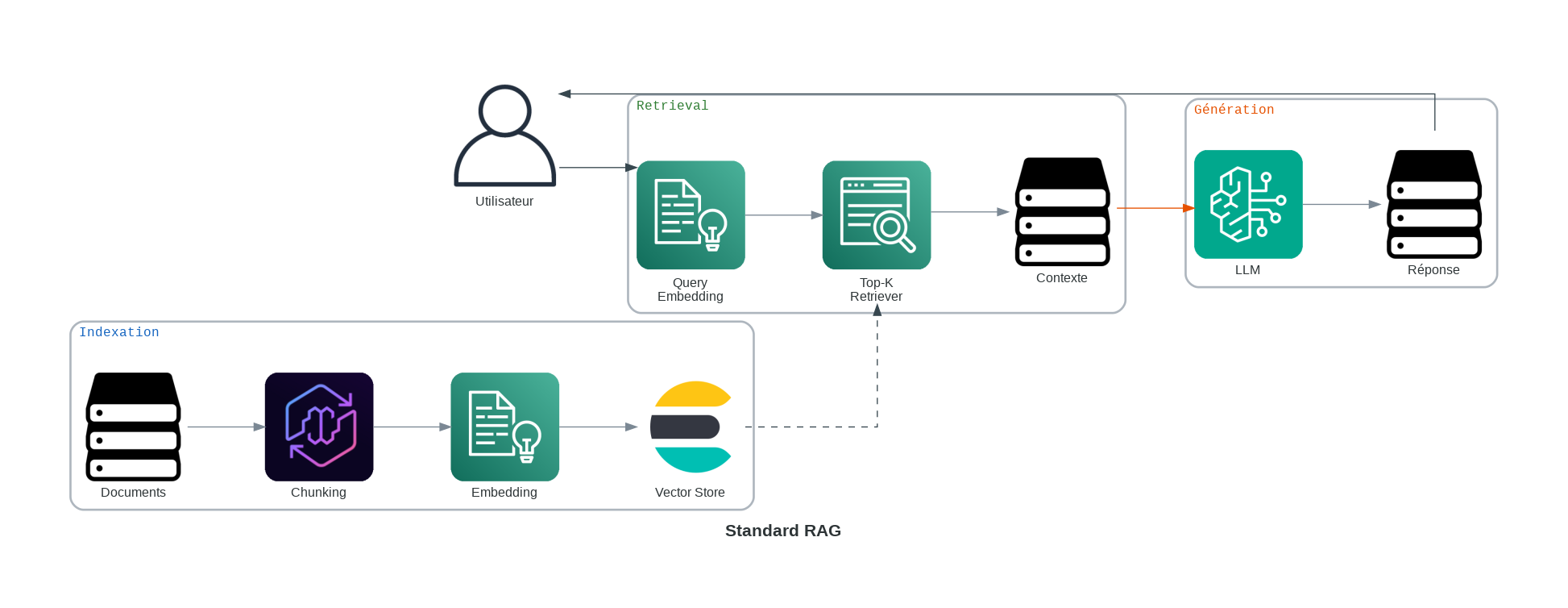
Le standard RAG traite la récupération comme une simple recherche ponctuelle. Il est idéal pour les environnements à faibles enjeux où la vitesse prime.
Le Standard RAG est le “Hello World” de l’écosystème. Il traite la récupération comme une simple recherche ponctuelle. Il existe pour ancrer un modèle dans des données spécifiques sans l’overhead du fine-tuning, mais il suppose que votre moteur de récupération est parfait.
Il convient le mieux aux environnements à faibles enjeux où la vitesse est plus importante que la densité factuelle absolue.
Comment cela fonctionne :
- Chunking (Segmentation) : Les documents sont divisés en petits segments de texte digérables.
- Embedding (Encodage) : Chaque segment est converti en vecteur et stocké dans une base de données (comme Pinecone ou Weaviate).
- Récupération : Une requête utilisateur est vectorisée, et les “Top-K” segments les plus similaires sont extraites à l’aide de la Similarité Cosinus.
- Génération : Ces segments sont fournis au modèle LLM en tant que “Contexte” pour générer une réponse ancrée.
Exemple Réaliste : Un bot d’handbook interne d’une petite startup. Un utilisateur demande, “Quelle est notre politique concernant les animaux de compagnie ?” et le bot récupère le paragraphe spécifique du manuel RH pour y répondre.
Avantages :
- Latence inférieure à une seconde.
- Coût computationnel extrêmement faible.
- Simple à déboguer et surveiller.
Inconvénients :
- Très sensible au “bruit” (récupération de segments irr pertinents).
- Aucune capacité de gérer des questions complexes en plusieurs parties.
- Manque d’auto-correction si les données récupérées sont incorrectes.
2. RAG Conversationnel : Ajout de la Mémoire
Conversational RAG résout le problème de “l’aveuglement au contexte”. Dans une configuration standard, si un utilisateur pose une question suivante comme “Combien ça coûte ?”, le système ne sait pas à quoi fait référence “ça”. Cette architecture ajoute une couche de mémoire étatful qui recontextualise chaque tour du chat.
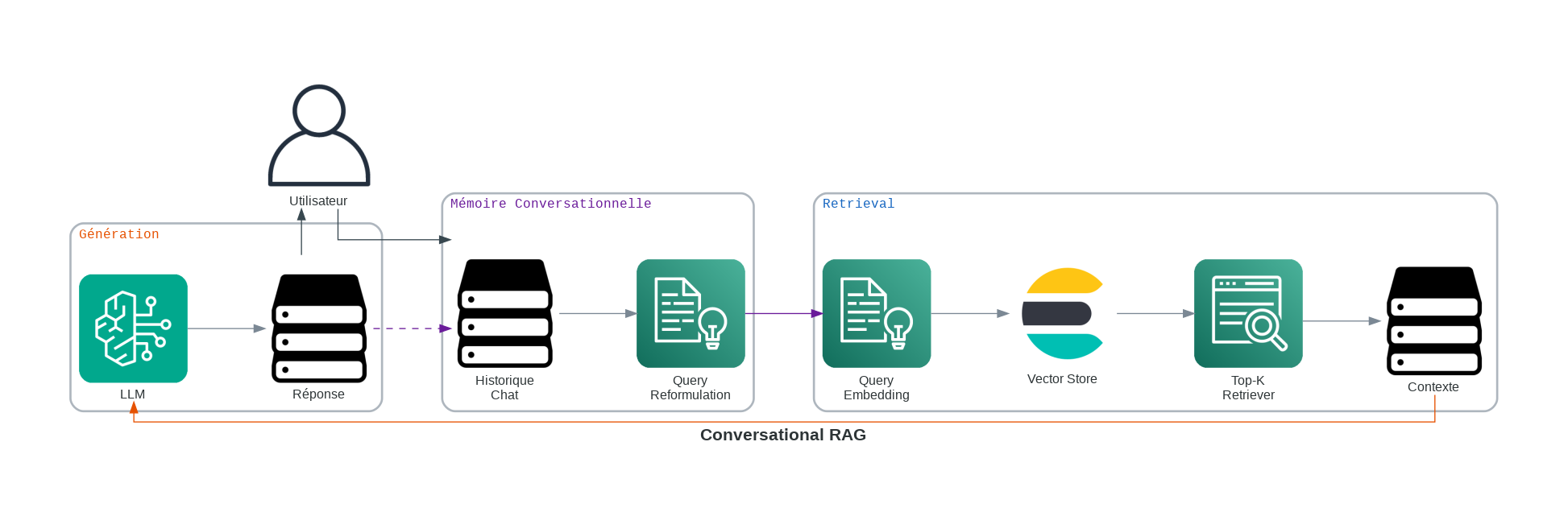
Comment cela fonctionne :
- Chargement du contexte : Le système stocke les 5-10 derniers tours de la conversation.
- Réécriture de la requête : Un LLM prend l’historique + la nouvelle requête pour générer une “Requête autonome” (par exemple, “Quel est le prix du Plan Entreprise ?”).
- Récupération : Cette requête étendue est utilisée pour la recherche vectorielle.
- Génération : La réponse est générée en utilisant le nouveau contexte.
Exemple réel : Un bot de support client pour une entreprise SaaS. L’utilisateur dit, “J’ai des problèmes avec ma clé API”, et suit par, “Pouvez-vous la réinitialiser ?” Le système sait que “ça” fait référence à la clé API.
Avantages :
- Fournit une expérience de chat naturelle et humaine.
- Empêche l’utilisateur d’avoir à se répéter.
Inconvénients :
- Drift du contexte : Un contexte irrélévant il y a 10 minutes peut polluer la recherche actuelle.
- Coûts plus élevés en tokens en raison de l’étape de “Réécriture de la requête”.
3. Corrective RAG (CRAG) : Le Vérificateur Auto
CRAG est une architecture conçue pour des environnements à haut risque. Il introduit un “Porte-de-décision” qui évalue la qualité des documents récupérés avant qu’ils ne parviennent au générateur. Si la recherche interne est mauvaise, elle déclenche un basculement vers le web en direct.
Dans les benchmarks internes rapportés par les équipes déployant des évaluateurs de type CRAG (Retrieval-Augmented Generation), les hallucinations ont été montrées diminuer par rapport aux baselines naïves.
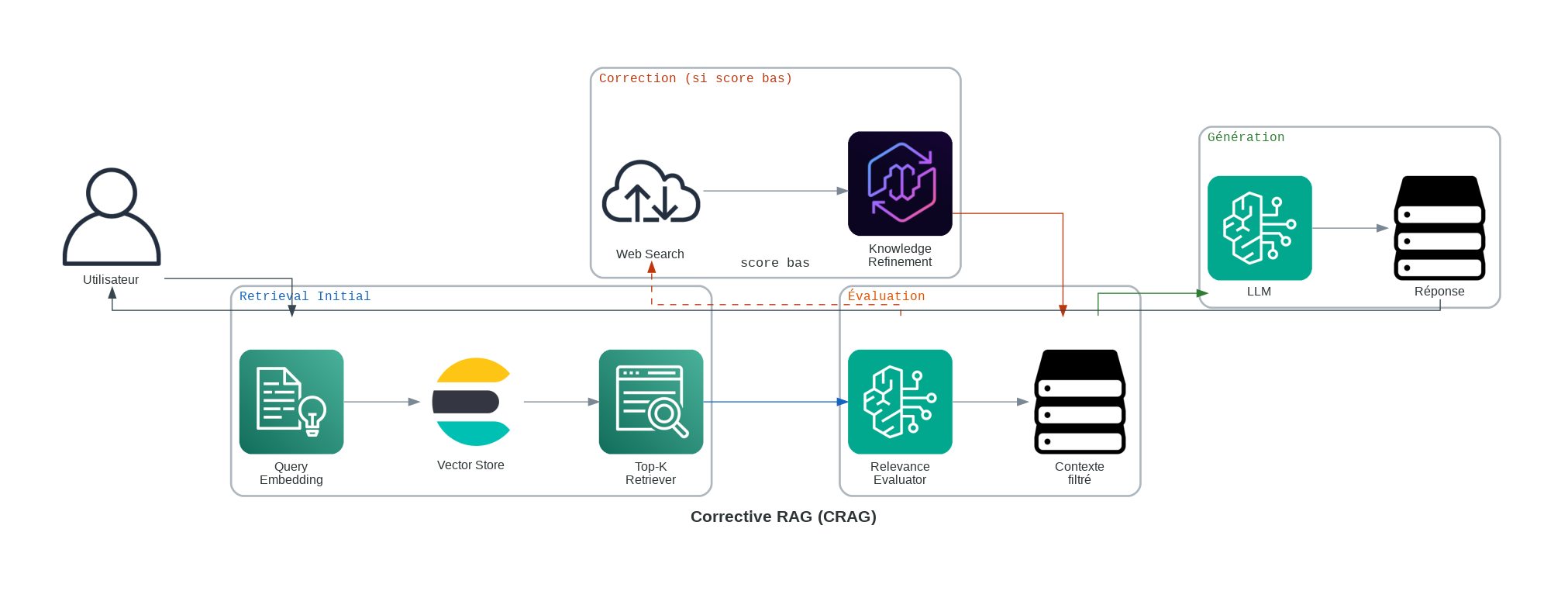
Comment cela fonctionne :
- Récupération : Récupérez des documents à partir de votre magasin interne de vecteurs.
- Évaluation : Un modèle léger appelé “Grader” attribue un score (Correct, Ambiguë, Incorrect) à chaque morceau de document.
- Porte de déclenchement :
- Correct : Passez au générateur.
- Incorrect : Ignorez les données et déclenchez une API externe (comme Google Search ou Tavily).
- Synthèse : Générez la réponse en utilisant les données internes vérifiées ou fraîches externes.
Exemple réel : Un bot conseiller financier. Lorsqu’il est interrogé sur un prix d’action spécifique qui n’est pas dans sa base de données 2024, CRAG reconnaît que les données sont manquantes et tire le prix actuel depuis une API de nouvelles financières.
Avantages :
- Réduit drastiquement les hallucinations.
- Relie l’écart entre les données internes et les faits réels du monde en temps réel.
Inconvénients :
- Augmentation significative de la latence (ajoute 2–4 secondes).
- Gestion des coûts et des limites de taux d’API externes.
4. RAG Adaptatif : Adapter l’effort à la complexité
Le RAG adaptatif est le “champion de l’efficacité”. Il reconnaît que chaque requête n’exige pas une arme à feu. Il utilise un routeur pour déterminer la complexité de l’intention de l’utilisateur et choisit le chemin le moins cher et le plus rapide vers la réponse.
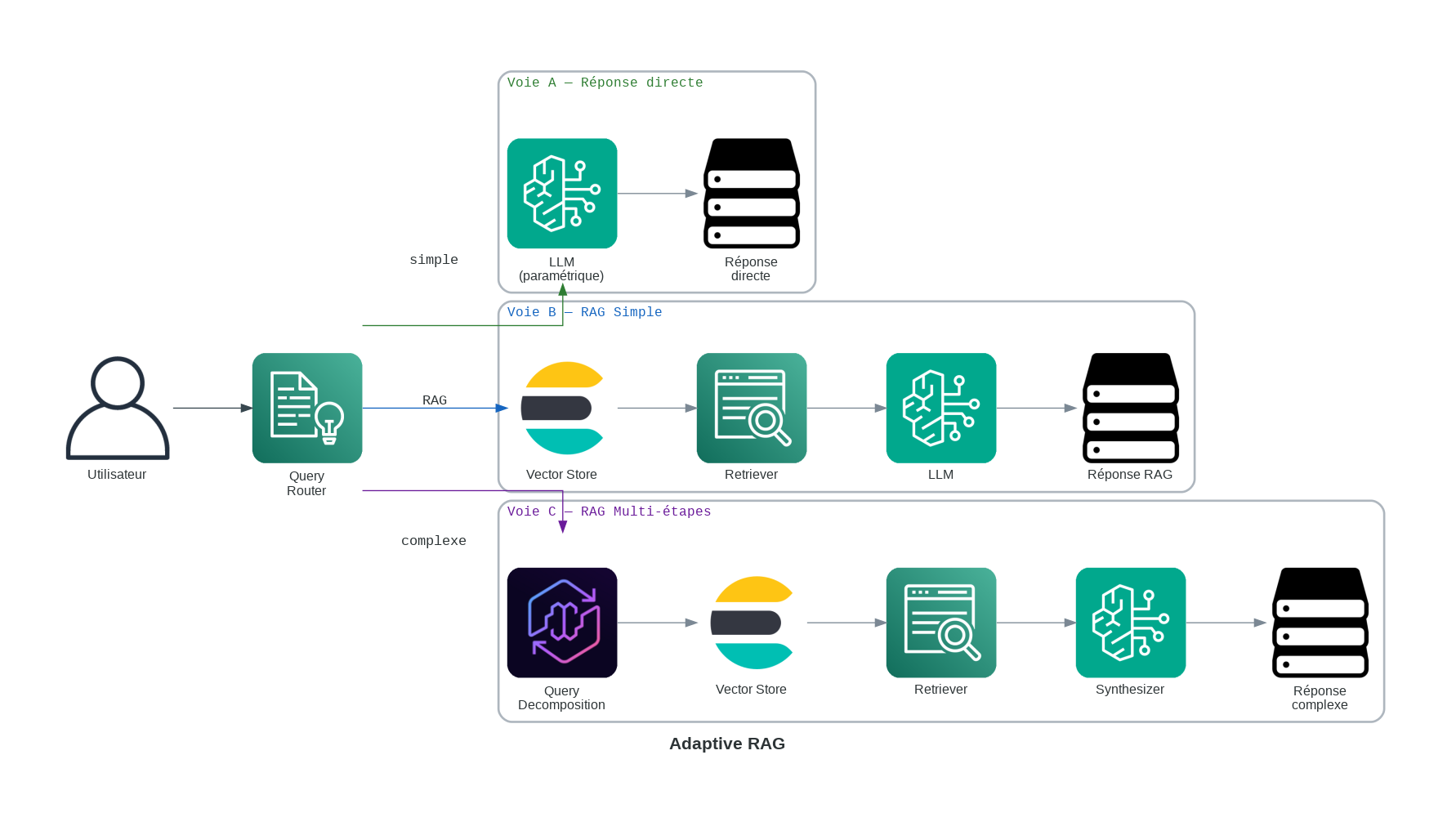
Comment cela fonctionne :
- Analyse de complexité : Un petit modèle classifieur dirige la requête.
- Chemin A (Aucune récupération) : Pour les salutations ou les connaissances générales, le LLM connaît déjà la réponse.
- Chemin B (RAG standard) : Pour les recherches factuelles simples.
- Chemin C (Agent multi-étapes) : Pour les questions analytiques complexes nécessitant des recherches dans plusieurs sources.
Exemple réaliste : Un assistant universitaire. Si un étudiant dit “Bonjour”, il répond directement. S’il demande “À quelle heure est ouvert la bibliothèque ?”, il fait une recherche simple. S’il demande “Comparez les frais de scolarité du programme informatique sur les 5 dernières années”, cela déclenche une analyse complexe.
Avantages :
- Économies massives en sautant des récupérations inutiles.
- Latence optimale pour les requêtes simples.
Inconvénients :
- Risque de mauvaise classification : Si le modèle pense qu’une question difficile est simple, il échouera à rechercher.
- Nécessite un modèle de routage extrêmement fiable.
5. Self-RAG : L’IA qui critique elle-même
Self-RAG est une architecture sophistiquée où le modèle est formé pour critiquer sa propre réflexion. Il ne récupère pas simplement des informations ; il génère des “jetons de réflexion” qui servent d’audit en temps réel de sa propre sortie.
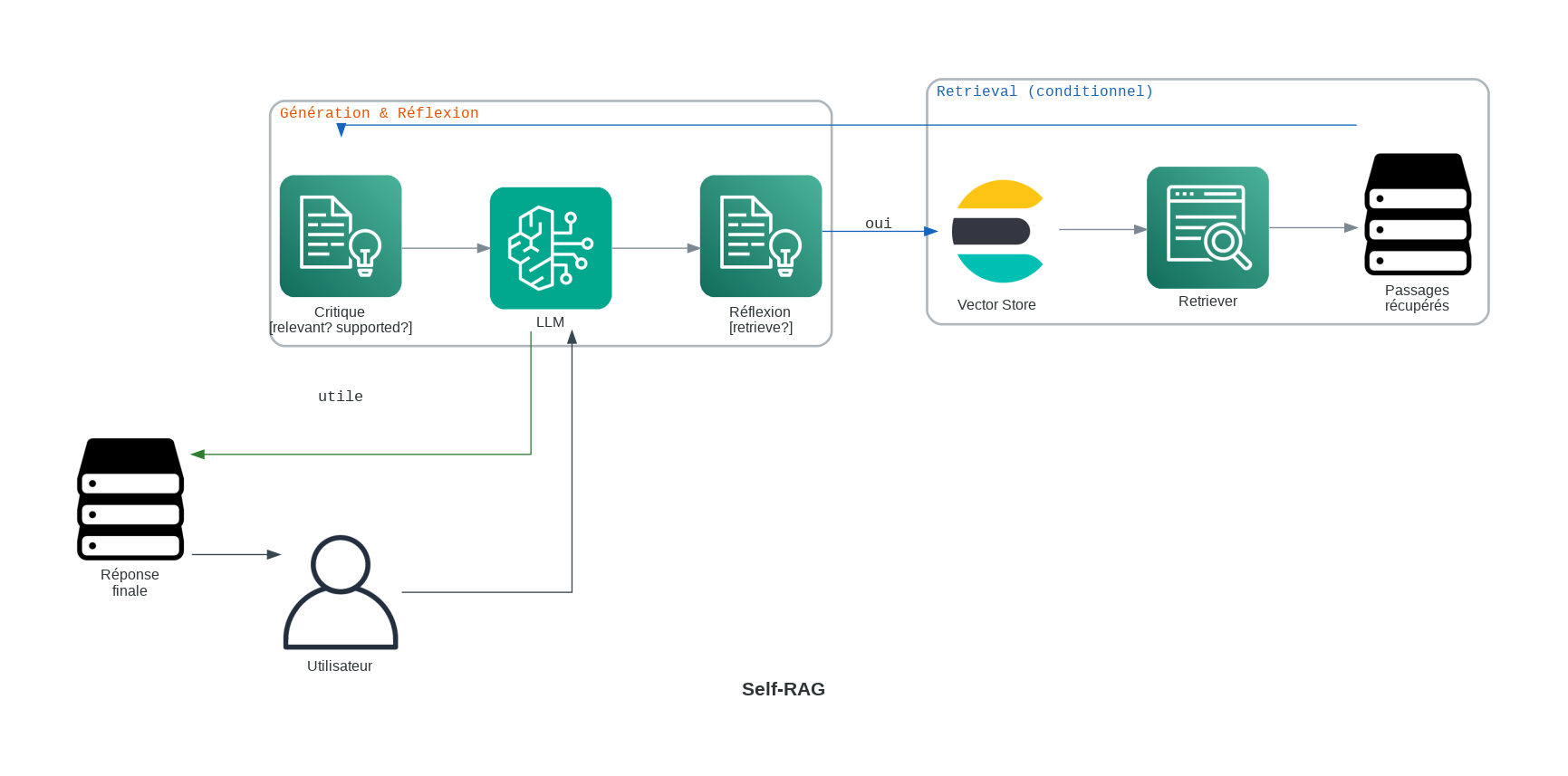
Comment cela fonctionne :
- Récupérer : Recherche standard déclenchée par le modèle lui-même.
- Générer avec des jetons : Le modèle génère du texte accompagné de jetons spéciaux comme
[IsRel](Est-ce pertinent ?),[IsSup](Cette affirmation est-elle soutenue ?) et[IsUse](Est-ce utile ?). - Auto-correction : Si le modèle produit un jeton
[NoSup], il s’arrête, re-récupère et réécrit la phrase.
Exemple Réaliste : Un outil de recherche juridique. Le modèle rédige une affirmation concernant un cas judiciaire, constate que le document récupéré ne soutient pas vraiment cette affirmation et effectue automatiquement une nouvelle recherche d’un précédent différent.
Avantages :
- Niveau le plus élevé de “fondement” factuel.
- Transparence intégrée pour le processus de raisonnement.
Inconvénients :
- Nécessite des modèles spécialisés et finement affinés (par exemple, Self-RAG Llama).
- Surcoût computationnel extrêmement élevé.
6. Fusion RAG : Plusieurs Perspectives, Meilleurs Résultats
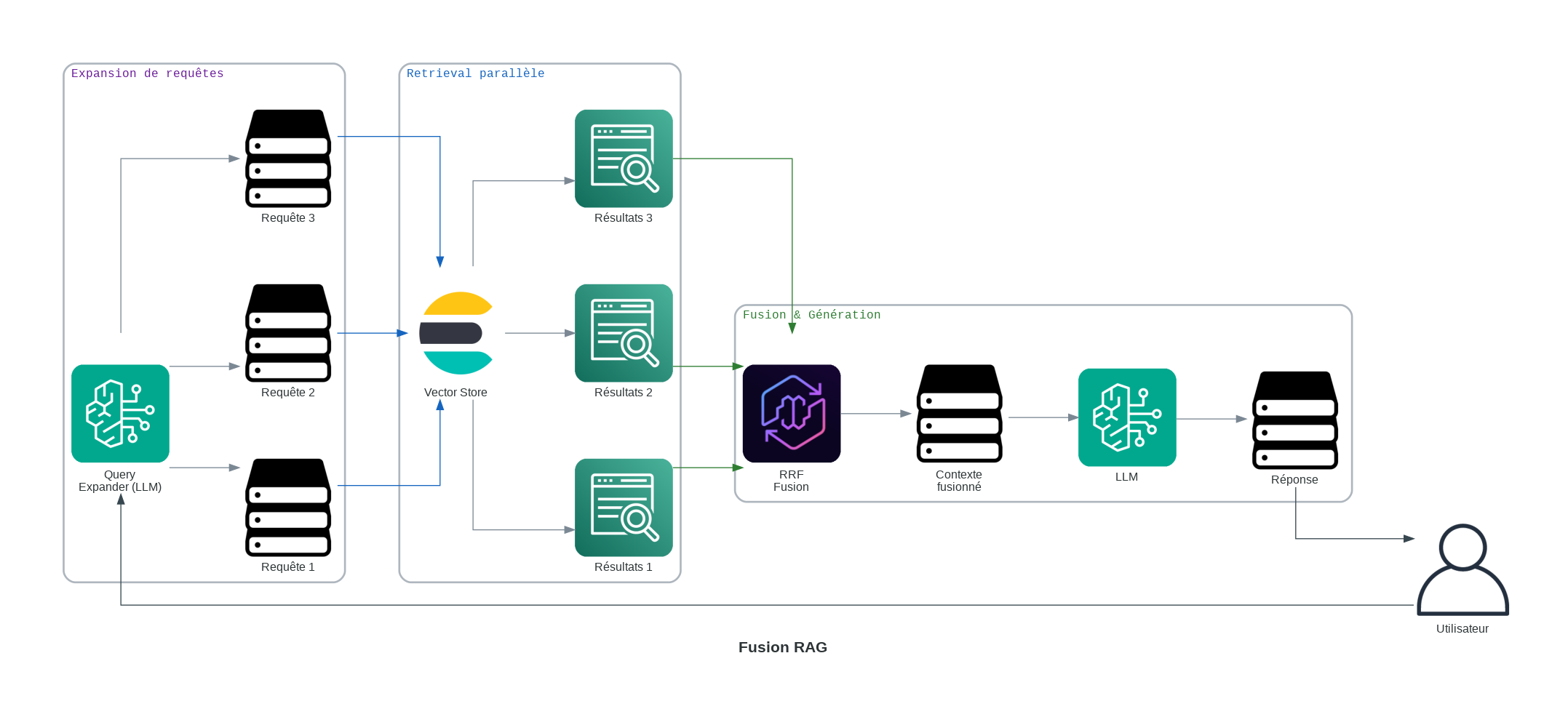
Fusion RAG aborde le “Problème de l’Ambiguïté”. La plupart des utilisateurs sont malhabiles en matière de recherche. Fusion RAG prend une seule requête et la considère sous plusieurs angles pour garantir une haute recall.
Comment Cela Fonctionne :
- Expansion de la Requête : Générer 3-5 variations de la question de l’utilisateur.
- Récupération Parallèle : Effectuer une recherche sur toutes les variations dans la base de données vectorielle.
- Fusion par Rang Reciproque (RRF) : Utiliser une formule mathématique pour réévaluer les résultats :
- Classement Final : Les documents qui apparaissent haut dans plusieurs recherches sont boostés en tête.
Exemple Réaliste : Un chercheur médical cherchant des “traitements de l’insomnie”. Fusion RAG effectue également une recherche sur les “médicaments pour le trouble du sommeil”, les “thérapies non pharmacologiques de l’insomnie” et les “protocoles CBT-I” pour s’assurer que aucun étude pertinente n’est manquée.
Avantages :
- Exceptionnelle recall (trouve des documents qu’une seule requête manquerait).
- Robuste à une formulation utilisateur défectueuse.
Inconvénients :
- Multiplie les coûts de recherche (3x-5x).
- Latence plus élevée en raison des calculs de réévaluation.
7. HyDE : Générez la Réponse, Puis Trouvez des Docs Similaires
HyDE est un modèle conceptuellement contre-intuitif mais brillant. Il reconnaît que les “Questions” et les “Réponses” sont sémantiquement différents. Il établit un pont entre eux en générant d’abord une “réponse fausse”.
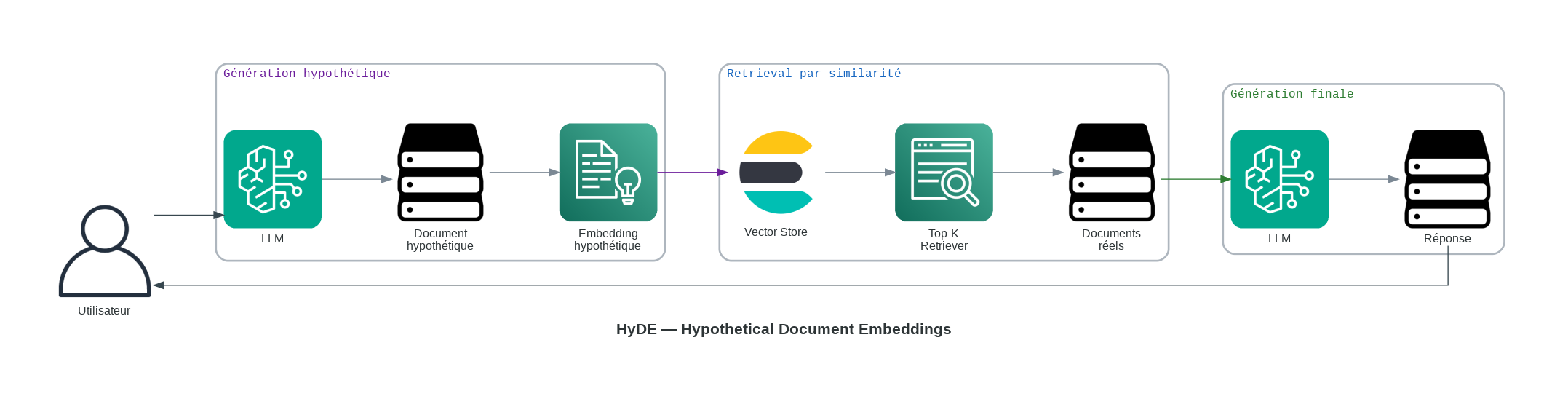
Comment cela fonctionne :
- Hypothétiser : Le LLM écrit une réponse fausse (hypothétique) à la requête.
- Vectorisation : La réponse fausse est vectorisée.
- Récupération : Utilisez ce vecteur pour trouver des documents réels qui ressemblent à la réponse fausse.
- Génération : Utilisez les documents réels pour écrire la réponse finale.
Exemple réaliste : Un utilisateur pose une question vague comme “Cette loi sur la vie privée numérique en Californie”. HyDE écrit un résumé faux du RGPD, utilise cela pour trouver le texte juridique réel du RGPD et fournit la réponse.
Avantages :
- Améliore considérablement la récupération pour les requêtes conceptuelles ou vagues.
- Aucune logique complexe d’« agent » requise.
Inconvénients :
- Risque de biais : Si la “réponse fausse” est fondamentalement incorrecte, la recherche sera trompée.
- Inefficace pour les recherches factuelles simples (par exemple, “Quelle est la somme de 2+2 ?”).
8. Agentic RAG : Orchestration des Spécialistes
Au lieu de récupérer aveuglément des documents, il introduit un agent autonome qui planifie, raisonne et décide comment et où récupérer les informations avant de générer une réponse.
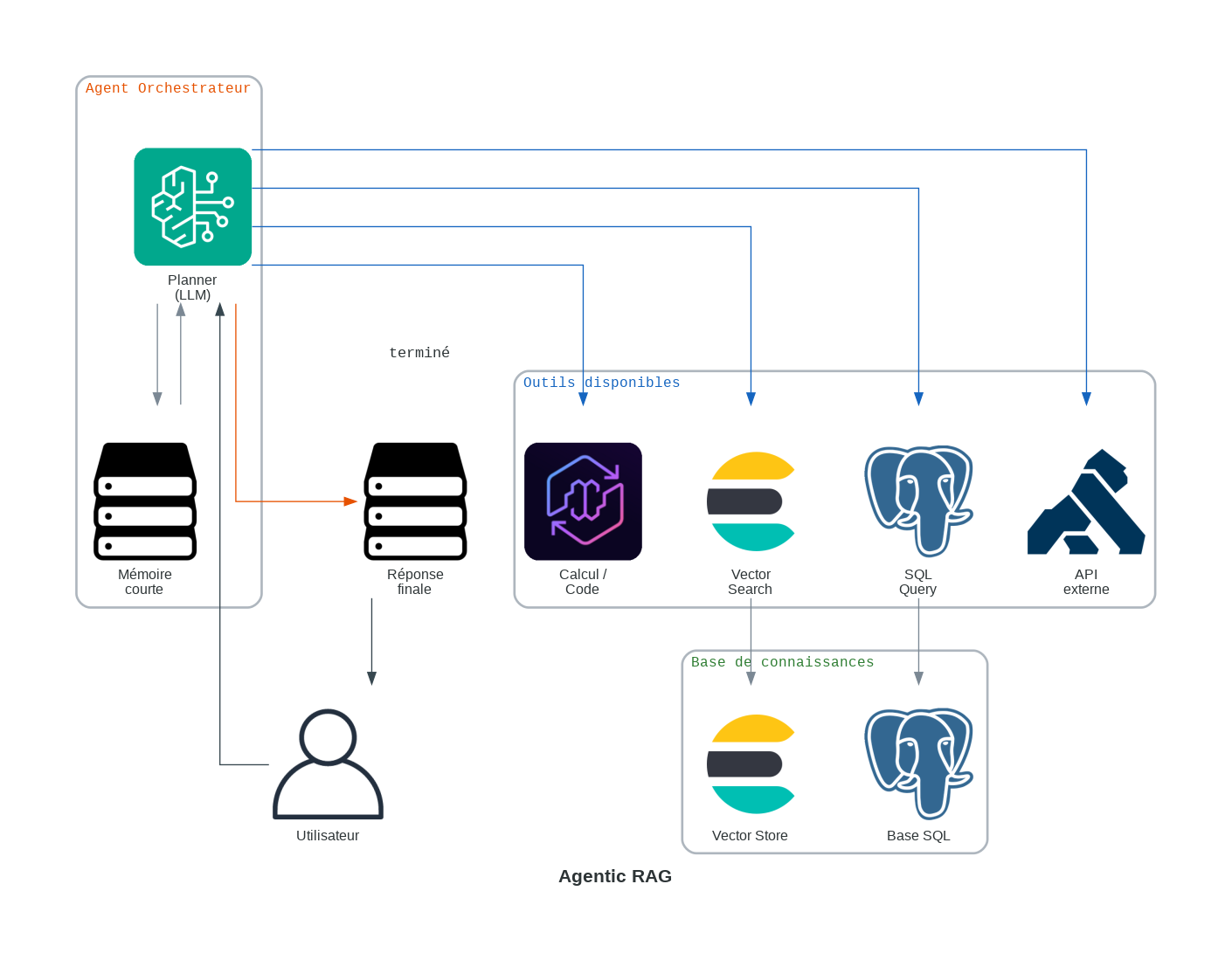
Il traite la récupération d’informations comme une recherche, pas une consultation.
- Analyser : L’agent interprète d’abord la requête de l’utilisateur et détermine s’il s’agit d’une requête simple, multi-étapes, ambiguë ou nécessitant des données en temps réel.
- Planifier : Il divise la requête en sous-tâches et décide d’une stratégie.
Par exemple : Faut-il effectuer une recherche vectorielle en premier ? Une recherche sur le web ? Appeler une API ? Poser une question de suivi ? - Agir : L’agent exécute ces étapes en invoquant des outils tels que les bases de données vectorielles, la recherche sur le web, les API internes ou les calculateurs.
- Itérer : Selon les résultats intermédiaires, l’agent peut affiner les requêtes, récupérer plus de données ou valider les sources.
- Générer : Une fois suffisamment d’évidences recueillies, le LLM produit une réponse finale solide et contextuelle.
Exemple Réaliste :
Un utilisateur demande :
“Est-il sûr qu’une application fintech utilise des LLM pour l’approbation de prêts conformément aux réglementations indiennes ?”
Agentic RAG pourrait :
- Détecter que c’est une question sur la réglementation, les politiques et le risque
- Rechercher les lignes directrices de la RBI via des outils web
- Récupérer les documents internes de conformité
- Vérifier les mises à jour récentes de la réglementation
- Synthétiser une réponse structurée avec des références et des avertissements
Un RAG traditionnel récupérerait probablement simplement des documents sémantiquement similaires et répondrait une fois.
Avantages :
- Gère les requêtes complexes, multi-étapes et ambiguës
- Réduit les hallucinations par la vérification et l’itération
- Peut accéder à des sources de données en temps réel et externes
- Plus adaptable aux contextes et aux exigences changeants
Inconvénients :
- Une latence plus élevée en raison de l’exécution multi-étapes
- Coûteux à exécuter que le simple RAG
- Nécessite une orchestration soignée des outils et des agents
- Exagération pour les requêtes factuelles simples
9. GraphRAG : Le Raisonneur de Relations
Alors que toutes les architectures précédentes récupèrent des documents en fonction de la similarité sémantique, GraphRAG récupère les entités et les relations explicites entre elles.
Au lieu de demander « quels textes ressemblent », il demande « ce qui est lié et comment ? »
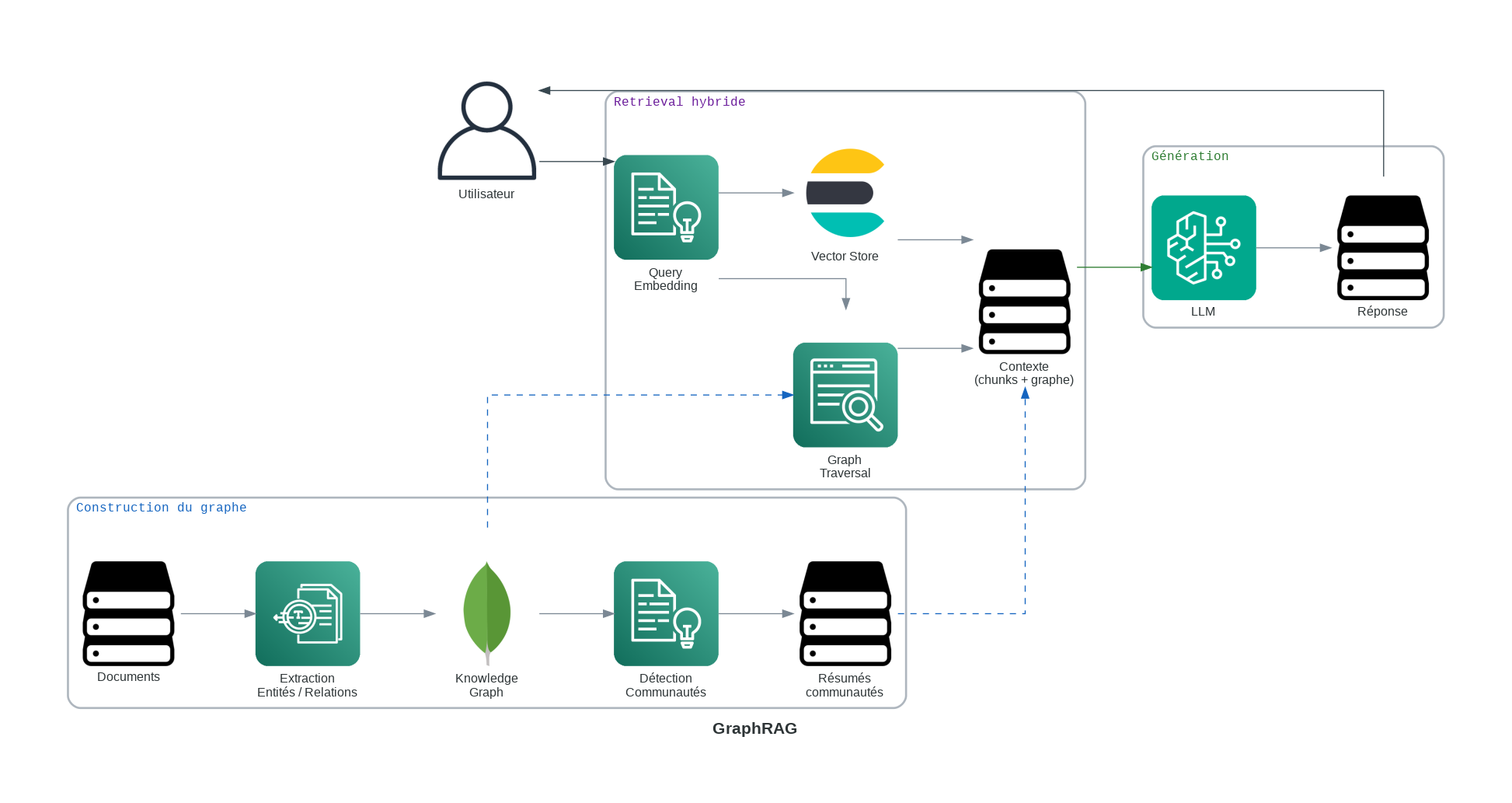
Comment cela fonctionne :
- Construction du graphe : Les connaissances sont modélisées sous forme de graphe où les nœuds sont des entités (personnes, organisations, concepts, événements) et les arêtes sont des relations (affecte, dépend_de, financé_par, régulé_par).
- Analyse de la requête : La requête utilisateur est analysée pour identifier les entités clés et les types de relations, pas seulement les mots-clés.
- Parcours du graphe : Le système parcourt le graphe pour trouver des chemins significatifs qui connectent les entités sur plusieurs étapes.
- Récupération hybride optionnelle : La recherche par vecteur est souvent utilisée en parallèle avec le graphe pour ancrer les entités dans du texte non structuré.
- Génération : Le LLM convertit les chemins de relations découverts en une réponse structurée et expliquable.
Exemple réaliste :
Requête :
« Comment les décisions d’intérêt des FED affectent-elles les évaluations des startups technologiques ? »
Parcours GraphRAG :
- Reserve fédérale → rate_decision → taux augmentés
- Taux augmentés → affectent → disponibilité des capitaux VC
- Disponibilité des capitaux VC réduite → impacte → évaluations de stade précoce
- Startups technologiques → financées_par → capital de risque
La réponse émerge du chaîne de relations, pas de la similarité documentaire.
Pourquoi C’est Différent :
- Vector RAG : “Quels documents sont similaires à ma requête ?”
- GraphRAG : “Quelles entités comptent, et comment elles s’influencent les unes les autres ?”
Cela rend GraphRAG beaucoup plus fort pour la raison causale, le multi-hop et la réduction déterministe.
Les systèmes combinant GraphRAG avec des taxonomies structurées ont atteint une précision proche de 99% dans les tâches de recherche déterministes.
Avantages :
- Excellent en raisonnement cause-effet
- Sorties hautement explicables grâce aux relations explicites
- Performance solide dans les domaines structurés et chargés de règles
- Réduit les faux positifs causés par la similarité sémantique
Inconvénients :
- Coût élevé au début pour construire et maintenir des graphes de connaissances
- La construction du graphe peut être coûteuse en termes de calcul
- Plus difficile à évoluer lorsque les domaines changent
- Excessif pour des requêtes ouvertes ou conversationnelles
Mise en œuvre on-premise : le socle commun
Les 9 architectures décrites ci-dessus partagent un socle technique commun lorsqu’elles sont déployées en environnement air-gapped (sans accès Internet). Le diagramme ci-dessous illustre les composants invariants — gateway API, serving IA, stockages et observabilité — sur lesquels chaque architecture s’appuie.
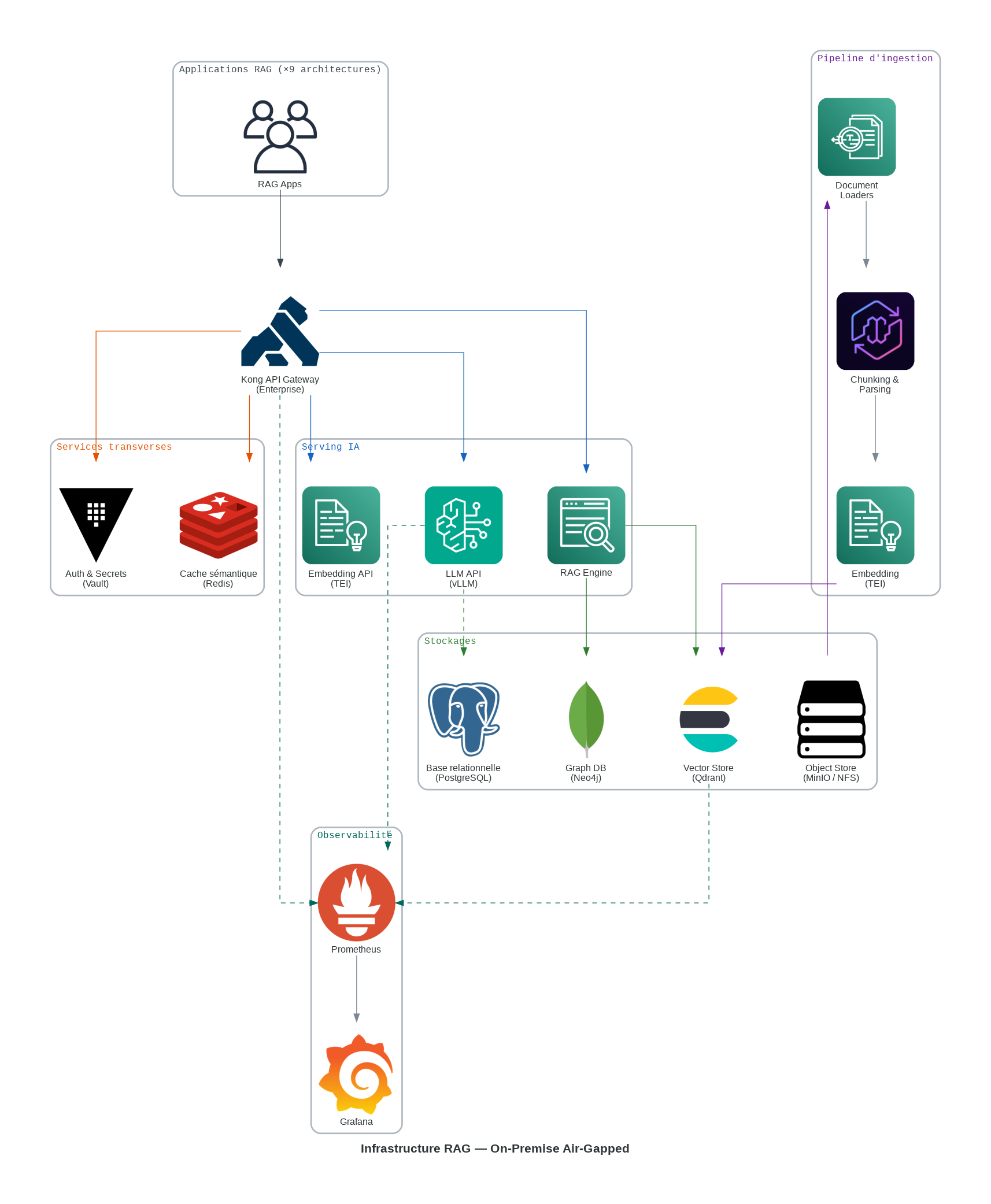
Kong fédère toutes les API internes (LLM via vLLM, embeddings via TEI, vector store via Qdrant). Neo4j est réservé aux architectures GraphRAG. Prometheus + Grafana assurent l’observabilité transverse. Aucun composant cloud n’est requis.
Comment Choisir Réellement (Le Cadre de Décision)
Étape 1 : Commencez par le RAG Standard
Sérieusement. Sauf si vous avez une preuve spécifique qu’il ne fonctionnera pas, commencez ici. Le RAG standard vous oblige à maîtriser les fondamentaux :
- Une découpe de document de qualité
- Des modèles d’embedding bons
- Une évaluation appropriée
- Un monitoring
Si le RAG standard ne fonctionne pas bien, la complexité ne vous sauvera pas. Vous aurez simplement un système compliqué qui continue de sucer.
Étape 2 : Ajouter de la mémoire uniquement si nécessaire
Les utilisateurs posent des questions suivantes ? Ajoutez Conversational RAG. Sinon, passez à l’étape suivante.
Étape 3 : Adapter l’architecture à votre problème réel
Regardez les requêtes réelles, pas celles idéales :
Les requêtes sont similaires et simples ? Restez avec Standard RAG. La complexité varie considérablement ? Ajoutez Adaptive routing. L’exactitude est une question de vie ou de mort ? Utilisez Corrective RAG malgré le coût. Les systèmes RAG en santé montrent des réductions de 15 % d’erreurs diagnostiques. Recherche ouverte ? Self-RAG ou Agentic RAG. Terminologie ambiguë ? Fusion RAG. Données relationnelles riches ? GraphRAG si vous pouvez vous permettre la construction du graphe.
Étape 4 : Considérez vos contraintes
Budget serré ? Standard RAG, optimisez la récupération. Évitez Self-RAG et Agentic RAG. Vitesse critique ? Standard ou Adaptive. DoorDash a atteint une latence de réponse vocale de 2,5 secondes, mais le chat doit être inférieur à 1 seconde. Exactitude critique ? Corrective ou GraphRAG malgré les coûts.
Étape 5 : Mélangez les architectures
Les systèmes de production combinent des approches : Standard + Corrective : Récupération standard rapide, fallback correctif pour une faible confiance. 95 % rapide, 5 % vérifié. Adaptive + GraphRAG : Les requêtes simples utilisent les vecteurs, les complexes utilisent les graphes. Fusion + Conversational : Variations de la requête avec mémoire.
La recherche hybride combinant des embeddings denses avec des méthodes creuses comme BM25 est presque standard pour le sens sémantique plus les correspondances exactes.
Analogy simple
Imaginez un LLM comme un employé intelligent avec un grand cerveau mais une mémoire terrible.
- Standard RAG est comme leur donner un cabinet de fichiers. Ils prennent un dossier, le lisent et répondent.
- Conversational RAG est le même employé qui prend des notes pendant la réunion pour ne pas poser les mêmes questions à nouveau.
- Corrective RAG ajoute un réviseur senior qui vérifie s’il y a vraiment une preuve de cela avant que la réponse ne parte.
- Adaptive RAG est un manager déterminant le niveau d’effort. Réponse rapide pour les questions faciles, recherche approfondie pour les plus difficiles.
- Self-RAG est l’employé qui pense à voix haute, s’arrêtant au milieu de la phrase pour chercher des informations quand il n’est pas sûr.
- Fusion RAG est d’interroger cinq collègues sur la même question sous différents angles et de faire confiance à ce qu’ils accordent.
- HyDE est l’employé qui brouilleur une réponse idéale en premier, puis cherche des documents qui correspondent à cette explication.
- Agentic RAG est un groupe d’experts. Le juridique, les finances et les opérations répondent chacun leur partie, puis quelqu’un les assemble.
- GraphRAG utilise un tableau blanc de relations au lieu de documents. Qui affecte qui, et comment.
Drapeaux rouges qui tuent les projets
Sur-Ingénierie: Agentic RAG pour les FAQ est une Ferrari pour les courses de courses. C’est gaspillant. Ignorer la qualité de récupération: Les récupérateurs à haute mémoire restent le socle de chaque système RAG. Une mauvaise récupération = une mauvaise génération, peu importe l’architecture. Pas d’évaluation: Vous ne pouvez pas améliorer ce que vous ne mesurez pas. Suivez la précision, la correction, la latence, le coût et la satisfaction dès le premier jour. Chasing Papers: Plus de 1 200 papiers RAG sont apparu sur arXiv en 2024 seul. Vous ne pouvez pas les mettre tous en œuvre. Concentrez-vous sur des approches prouvées pour vos problèmes spécifiques. Skipping Users: Que veulent vraiment les utilisateurs ? Parlez-en à eux. De nombreuses équipes construisent des solutions complexes pour des problèmes que les utilisateurs n’ont pas tout en ignorant de vrais problèmes.
Le Point Final
RAG n’est pas une magie. Il ne corrige pas un mauvais design ou des données de qualité. Mais mis en œuvre avec soin, il transforme les modèles linguistiques de menteurs confiants en systèmes d’information fiables.
En 2025, RAG sert d’imperatif stratégique pour les entreprises, fournissant la couche de confiance nécessaire aux entreprises pour adopter en toute sécurité l’IA générative.
Les huit architectures résolvent des problèmes différents :
- Standard : Rapide, simple, commencez par ici
- Conversational : Ajoute une mémoire pour les échanges multirounds
- Corrective : Valide la qualité, haute précision
- Adaptive : Alloue des ressources en fonction de la complexité
- Self-RAG : Raisonnement autonome, très coûteux
- Fusion : Plusieurs angles pour les requêtes ambiguës
- HyDE : Relie les écarts sémantiques conceptuellement
- Agentic : Orchestre des spécialistes, le plus complexe
- GraphRAG : Raisonnement sur les relations pour les données connectées
Le meilleur système n’est pas celui qui est le plus sophistiqué. C’est celui qui sert fiablement vos utilisateurs dans vos contraintes.
Commencez simplement. Mesurez tout. Augmentez la complexité uniquement avec des preuves claires qu’il en a besoin. Maîtrisez les fondamentaux d’abord.