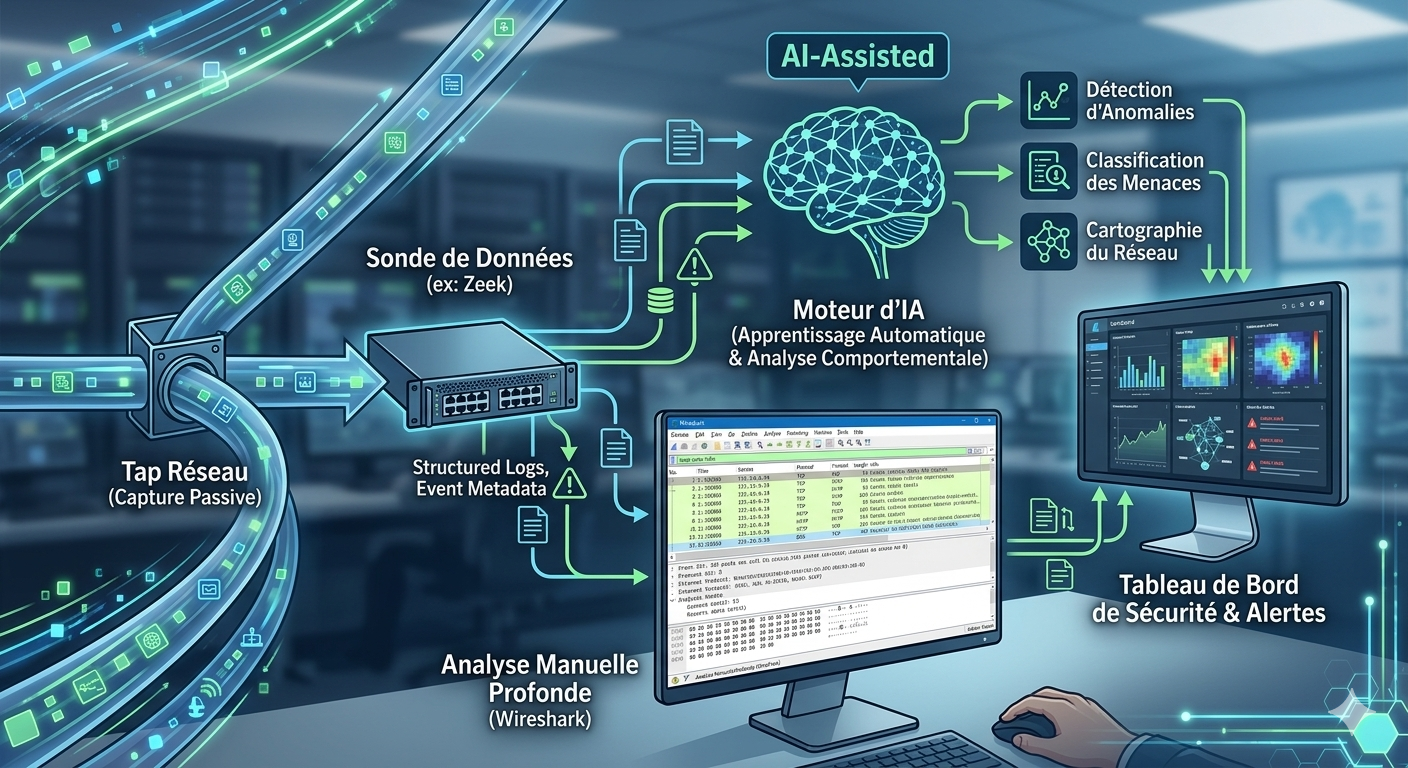
Détection réseau par IA · N°1
La détection d’intrusion réseau par intelligence artificielle est souvent présentée comme une boîte magique : « on branche l’IA sur le réseau et elle trouve les attaques ». La réalité est plus terre à terre — et bien plus intéressante pour qui doit la mettre en œuvre. Derrière le buzzword, il y a un pipeline parfaitement classique, et un maillon qui décide de tout : le prétraitement. C’est aussi lui dont le coût matériel explose dès qu’on monte en débit.

Inférence LLM CPU · N°1
Benchmarker llama.cpp sur CPU : ce qu’on apprend en 50 runs Résumé Exécutif Pour les besoins d’un PoC SOC agentique CPU-only, j’ai fait tourner ~50 benchmarks llama-bench sur 4 plateformes différentes (un Ryzen 5 3600 bare-metal, sa contrepartie FreeBSD, un EPYC Milan dedicated chez Hetzner, un Xeon Skylake shared chez Hetzner). Modèle de référence : Qwen 2.5 3B Q4_K_M et son grand frère 7B. Builds comparés : llama.cpp (tag b3813 et b9165) et son fork agressif ik_llama.
Inférence LLM CPU · N°2
tg/s = MB/s : la formule empirique pour planifier la capacité d’un cluster LLM CPU TL;DR Sur 5 plateformes CPU (x86 AMD, x86 Intel, ARM Ampere Altra), la bande passante mémoire (mesurée par mbw) prédit le throughput de génération LLM (tg64 sur Qwen 3B Q4_K_M) à ±10 % près sur x86 et à ±25 % près si on inclut ARM. Le ratio empirique est ~470 MB par token/s sur x86, et ~650 MB par token/s sur ARM Ampere Altra — l’ARM est moins efficient par MB de BW pour des raisons développées plus loin.
Inférence LLM CPU · N°3
FreeBSD pour l’inférence LLM embarquée : un non-sujet TL;DR Sur le même CPU (AMD Ryzen 5 3600, Zen 2), le même tag llama.cpp, le même modèle (Qwen 2.5 3B Q4_K_M), le même nombre de threads — Linux Debian 12 et FreeBSD 14.4 produisent des t/s quasi identiques :
OS tag llama.cpp t=6 pp256 t=6 tg64 Linux Debian 12 b9165 90.6 17.1 FreeBSD 14.4 b9000 90.5 16.7 Différence < 1 % sur le pp, ~2 % sur le tg — dans la marge d’erreur des mesures successives.
Inférence LLM CPU · N°4
Quatre challengers pour llama.cpp sur CPU : ce qui passe et ce qui casse TL;DR Après les 50 benchs de llama.cpp et ik_llama.cpp du premier article de cette série, une question logique : est-ce qu’un autre moteur CPU pourrait faire mieux que llama.cpp HEAD sur mon Ryzen 5 3600 ? J’ai testé quatre candidats régulièrement cités :
Moteur Promesse Résultat sur Ryzen Zen 2 Verdict vLLM CPU Continuous batching multi-request Échec d’install (3 tentatives) À reprendre via Docker CTranslate2 Mature, INT8 historique -46 % vs llama.

SOC Agentique — asp-forge · N°1
Cet article ouvre une série de trois consacrée à asp-forge, un lab de Security Operations Center agentique entièrement auto-hébergé, conçu comme banc d’essai pour évaluer l’apport concret des modèles de langage dans le triage d’alertes. Cible : DevSecOps et analystes SOC qui s’interrogent sur l’industrialisation des LLM dans une chaîne de réponse aux incidents, sans dépendre d’un fournisseur cloud.
Le problème : la fatigue d’alertes ne se résout pas par plus d’analystes Tout SOC un peu sérieux remonte plusieurs centaines à plusieurs milliers d’événements par jour depuis ses outils — Wazuh sur les serveurs, T-Pot sur les honeypots exposés, les EDR sur les postes, les WAF en bordure.
SOC Agentique — asp-forge · N°2
Deuxième volet de la série asp-forge. Après les choix structurants posés dans le premier article, on entre dans le cœur du système : comment plusieurs agents LLM collaborent sur une même alerte, et pourquoi cette collaboration est organisée en cascade plutôt qu’en agent unique.
Pourquoi une cascade et pas un seul agent ? L’instinct premier, quand on dispose d’un LLM 3 milliards de paramètres qui raisonne correctement, est de lui confier l’intégralité de la décision : alerte en entrée, verdict en sortie.
SOC Agentique — asp-forge · N°3
Troisième et dernier volet de la série asp-forge. Après l’architecture (article 1) et le pipeline cascade (article 2), il reste la question qui intéresse vraiment l’ingénieur : qu’est-ce qui s’est mal passé, qu’est-ce qui a surpris, et qu’est-ce qu’on garde pour la suite ? Pas de success story édulcorée — on partage les pièges réels.
Bug LoRA dynamique : une discipline de version pinning Premier piège qui a coûté plusieurs jours de débogage.

Agents en Production · N°1
Dans la série LoRA Factory, nous avons construit une usine à agents spécialisés sur Phi-3.5-mini-instruct. Trois agents (OPNsense, WireGuard, CrowdSec), trois adapters LoRA, un pipeline d’entraînement automatisé.
Tout fonctionnait — jusqu’à ce que les limites du modèle de base se manifestent en production. Ce premier article de la série Agents en Production documente pourquoi et comment nous avons migré vers Qwen2.5-3B-Instruct.
Pourquoi changer de modèle de base ? Phi-3.5-mini est un excellent modèle compact.

Agents en Production · N°2
C’est le type de bug qu’on ne voit pas venir.
L’entraînement se termine normalement. La loss finale est bonne — 0.2532 pour OPNsense, comparable aux runs précédents. Pas d’anomalie dans les courbes. Le modèle a convergé.
Puis on lance la vérification fonctionnelle. Et le score tombe à zéro.
Score : 0/102 (0%) ❌ ADAPTATEUR NON VALIDÉ L’investigation La première réaction est de chercher un bug dans le script de vérification. On inspecte le chargement du modèle, l’application de l’adapter, le décodage.
Agents en Production · N°3
Après entraînement, la question n’est pas “quelle est la loss ?”, c’est “l’agent appelle-t-il la bonne fonction quand on lui donne une directive réelle ?”.
C’est cette distinction qui a motivé la construction d’un système de vérification comportementale, distinct et indépendant du pipeline d’entraînement.
Le format CAP v1 Le coordinateur communique avec les agents via un format structuré appelé CAP v1 (Coordinator-Agent Packet). C’est le format de production — ce que reçoit l’agent dans un déploiement réel.
Agents en Production · N°4
Les trois agents sont validés à 100%. La question devient : comment les servir simultanément sur un GPU de 12 Go déjà occupé par le coordinateur ?
Le problème du multi-agent sur GPU contraint L’architecture cible est simple :
Utilisateur │ ▼ Coordinateur (Qwen2.5-3B, port 3001) │ CAP v1 ├──→ OPNsense agent ├──→ WireGuard agent └──→ CrowdSec agent │ ▼ Tool-agent-server (port 3000) Le coordinateur et les agents-outils tournent sur le même GPU — une RTX 4070 Ti avec 12 Go de VRAM réels (11.
