
victor_le_nettoyeur
Suite directe du bilan v3.11. Ce cycle a trois étapes : migration de l’architecture tok2vec vers un transformer, diagnostic systématique des faux négatifs par label, puis correction ciblée des causes racines identifiées. Résultat : F1 global 88% → 95,9%.
Contexte v3.12→v3.14 — Entre v3.11 et v3.14, trois cycles d’amélioration ont produit des résultats décevants : ajout de 500 exemples synthétiques EC2 pour HOSTNAME (+2 points de recall), tentatives de rééquilibrage des labels PID et MAC_ADDRESS.
victor_le_nettoyeur
Suite directe du bilan v3.16. Ce cycle couvre trois corpus successifs (v3.17, v3.18, v3.19) et trois problèmes distincts : améliorer URL_URI qui plafonnait à 80.9%, corriger SCHEDULED_TASK à 0%, et isoler un nouveau label KEY_FINGERPRINT du label FILE_HASH.
Corpus v3.17 — Diagnostic URL_URI Analyse des faux négatifs L’article précédent concluait sur URL_URI à 80.9% avec 66 FN. Le script analyze_fn.py donnait :
Total FN URL_URI : 66 Labels prédits à la place de URL_URI : — 66 (100.

Important Traduction du site Source
Cet article est la version Française de 9 RAG Architectures Every AI Developer Should Know: A Complete Guide with Examples par Auteur Inconnu.
9 Architectures RAG : Un Guide Complet Avec Des Exemples
TLDR Le RAG optimise les sorties des modèles linguistiques en les faisant référencer des bases de connaissances externes avant de générer des réponses. Le RAG convient le mieux aux environnements à faible risque où la vitesse est plus importante que la densité factuelle absolue.

Note Article importé du site Source
Cet article est la version Française de Petits modèles linguistiques : Un guide avec des exemples | DataCamp par Auteur Inconnu.
Que sont les petits modèles linguistiques ? Les petits modèles linguistiques sont les versions compactes et très efficaces des grands modèles linguistiques massifs dont nous avons tant entendu parler. Les LLM comme le GPT-4o ont des centaines de milliards de paramètres, mais les SML en utilisent beaucoup moins, généralement de l’ordre de quelques millions à quelques milliards.
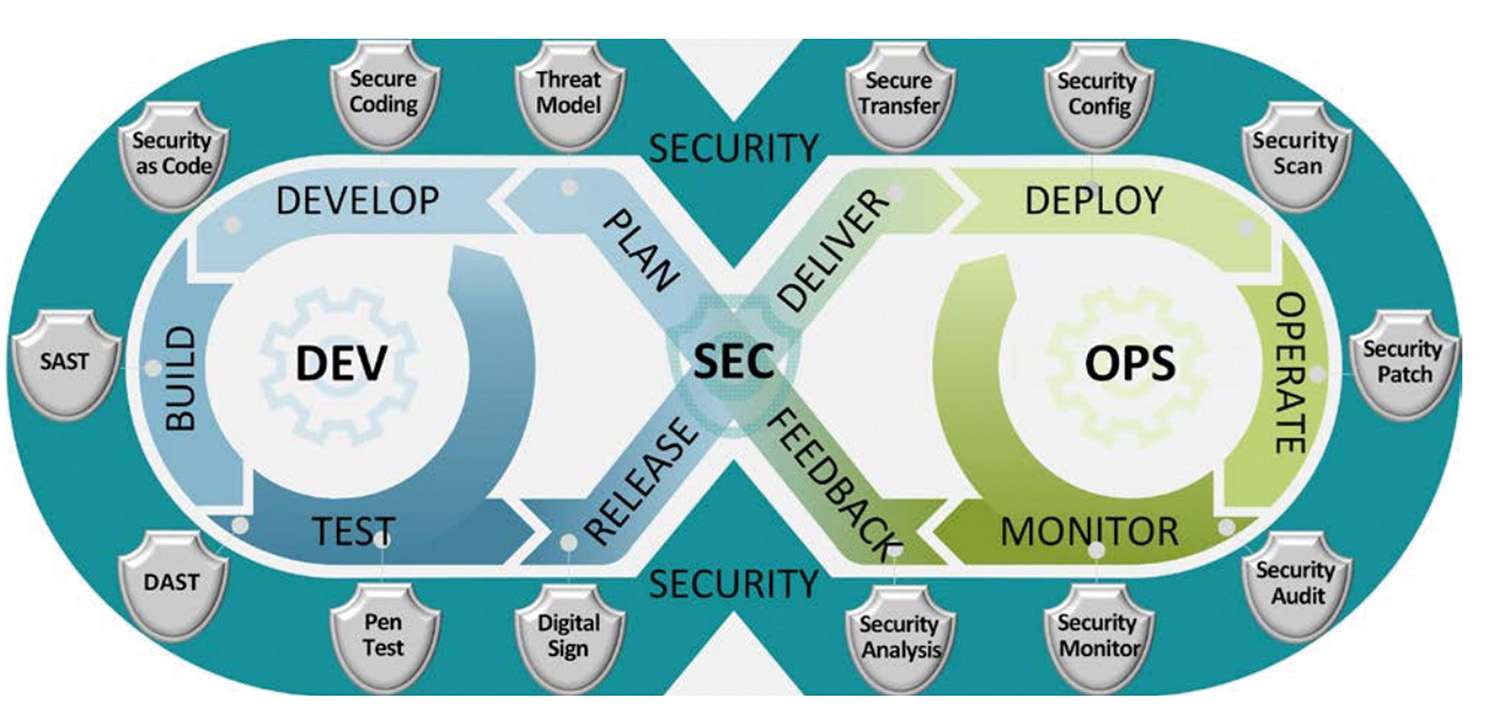
Rapport Stratégique et Méthodologique : Développement d’assistants spécialisés LoRA pour l’accélération et la fiabilisation du cycle DevSecOps Résumé Exécutif (Management Summary) Réponse à la Faisabilité : Oui, la création d’un adaptateur LoRA (Low-Rank Adaptation) pour le domaine DevSecOps est non seulement concevable, mais elle représente une évolution stratégique majeure pour les organisations matures en matière de sécurité. Cependant, l’approche de la création d’un “LoRA DevSecOps” monolithique est fondamentalement erronée et vouée à l’échec.

Important En cours
Le contenu de cette page est en cours d’édition. Découverte de Qwen Coder 2.5 : Le LLM d’Alibaba pour les développeurs Introduction à Qwen Coder 2.5 Qwen Coder 2.5 est un grand modèle de langage (LLM) développé par l’équipe Qwen d’Alibaba Cloud, spécialement conçu pour les tâches de programmation. Il se distingue par ses capacités avancées en génération, raisonnement et correction de code, prenant en charge plus de 90 langages de programmation, dont Python, Java, C++, et bien d’autres.
